From a raw keyword list to ranked pages — collect, cluster, write, audit, link.
Most advice on choosing keywords for a real estate website stops at the easy part. “Use Google Keyword Planner, target what your audience searches.” Fine. But that skips every decision that actually decides whether the site ranks — which keyword goes on which page, how to stop two of your own pages from fighting each other, why one blog post gets indexed and another just sits there ignored. The keyword-finding bit was never the hard bit.
So instead, here’s the full thing — the sequence I run on property sites from start to finish. I’m going to lean on one project as I go: a real estate site on a resort-market niche, where we rebuilt the keyword structure from nothing. One particular decision on that project, about how to handle the filter pages, ended up doing most of the work, and I’ll get to it. To be clear, none of this is clever. It’s ordinary steps in a deliberate order, and it’s the order that matters.
If you only remember one line from this, remember that the best keywords for a real estate website are almost never the ones with the biggest search numbers. They’re the ones you can actually win, put on pages that don’t overlap. Volume is the column beginners stare at. It’s mostly the wrong column.
The first mistake I see on property sites is starting too narrow. Someone lists ten obvious phrases off the top of their head — “villas for sale,” “property for rent” — builds pages for those, done. But the real estate search space is much wider than the obvious head terms, and most of the traffic you can realistically win is hiding in phrasings nobody thinks to write down from memory.
So step one is just collection. Gather everything, judge nothing yet. On the agency project we pulled the complete set of phrases people use around buying and renting in that market: property types, locations down to the district, the intent variations (buy, rent, long-term, investment), and the long conversational queries people increasingly type out in full. You’re building raw material here, not a plan. The judging comes later.
For the gathering itself, there are two practical routes and they have a real trade-off. A big keyword tool like SemRush gives you enormous breadth — it surfaces phrases you would simply never brainstorm. The catch, at least in my experience, is that all that breadth often comes without dependable local search volume, which is a problem in smaller property markets. A dedicated keyword research tool tends to hand you volume and difficulty together, and you’ll want those numbers for the next steps. We use the keyword tool in our own toolkit, Algorithm, for that part, though the point stands whatever you reach for. Honestly on a serious project I just use both — one for reach, one for the numbers — and accept the overlap. Either way you should come out of this step with a long, messy, unsorted list. Messy is fine. Messy is the correct state of things at this stage.
Before the sorting starts, it helps to see the raw shape of the space you’re collecting from. Real estate keywords for a website tend to fall into a few predictable buckets, and the best keywords for a real estate website are almost always the specific, lower-competition phrases inside them — not the one-word head terms at the top. Swap [area] for a real district or city and these are the patterns to gather:
That last bucket is a different job from the rest — it belongs on articles, not landing pages, and I come back to it in step 4. The point of listing them together is to show the range: a property site that only chases “property for sale” is ignoring the nine-tenths of demand sitting in the specific phrases underneath it.
Here’s the part that makes a resort market different, and it’s worth pausing on. The demand for property in a place like Bali doesn’t come from Bali. It comes from buyers sitting in other countries — the US, Australia, and locally within Indonesia — and each of those audiences searches in different volumes, at different difficulty. So when we collected the keyword set, we collected it per country, not once. Same phrases, three different demand profiles.
A slice of the actual data from that project, pulled per country in SemRush:
| Keyword | US | Australia | Indonesia | |||
|---|---|---|---|---|---|---|
| Vol | KD | Vol | KD | Vol | KD | |
| bali real estate | 1,300 | 52 | 1,300 | 61 | 1,300 | 46 |
| real estate in bali | 320 | 32 | 320 | 59 | 1,300 | 51 |
| bali property for sale | 480 | 38 | 880 | 55 | 720 | 39 |
| bali real estate sale | 210 | 44 | 720 | 57 | 110 | 44 |
| real estate bali for sale | 480 | 41 | 480 | 54 | 30 | 40 |
| bali real estate for sale | 390 | 41 | 260 | 55 | 140 | 44 |
| property for sale in bali indonesia | 210 | 34 | 320 | 44 | 20 | 10 |
| property for sale in bali | 110 | 30 | 110 | 30 | 720 | 49 |
| bali properties for sale | 50 | 15 | 50 | 15 | 720 | 46 |
Read across any single row and the point jumps out. “bali real estate” pulls the same 1,300 searches in all three markets, but its difficulty swings from 46 in Indonesia to 61 in Australia — because KD is measured against each country’s own search results, while volume is the demand coming out of that country. The same keyword is a different fight depending on who you’re competing with. A phrase that’s a hard climb for an Australian audience can be a realistic win for a US one, and you only see that if you pull the data per country instead of once.
The low-KD rows are where the quick wins hide. “property for sale in bali indonesia” sits at KD 10 in Indonesia, “bali properties for sale” at 15 in both the US and Australia. Lower volume, far lower competition, clear buyer intent — those are the on-ramp pages. The bare head term “bali real estate”, high volume and KD in the 50s and 60s, belongs on a main section page you climb toward, not a quick win.
Every one of those rows is a cluster, and every cluster wanted its own clean landing page — site.com/buy/villas/… — rather than one generic page trying to rank for all of them at once and cannibalizing itself. Multiply this across types, districts, bedroom counts and tags, and across the source countries, and you can see how the demand data alone produced the ~450 pages. Nothing speculative — just every combination a real person was actually searching for. (The broken parameter URLs that usually kill this, and the other structural mistakes behind it, are something I broke down separately in common website issues for real estate agents.)
This is the step most guides skip, and skipping it is how you walk straight into the most expensive mistake on any content-heavy site: keyword cannibalization. That’s when two of your own pages chase the same intent, split their signals between them, and end up dragging each other down so neither one ranks properly.
Here’s the thing a raw keyword list is not: it’s not a content plan. Before a single page exists, the list has to be grouped by intent. Every keyword that represents the same underlying need goes into one cluster, and one cluster becomes one page. “Buy villa” and “villa for sale” — same intent, same page. “Buy villa” and “rent villa long term” — different intent, and they should never land on the same page. Do the grouping properly and the site structure basically falls out of it on its own: every cluster is a page, no two pages overlap.
For a short list you can cluster by hand. For a real property site you’re looking at hundreds of keywords, and honestly manual grouping starts to fall apart somewhere in the middle — you lose your own consistency without noticing. So this is one to do with a clustering tool. The one we built into Algorithm has three modes; the one I trust most groups keywords by which pages already rank together in Google’s top results, because that clusters them by how Google itself treats them rather than how they look to a human eye. Use whatever tool you like. What you need out of it is one thing: a clean map of cluster to page, with no intent showing up twice.
This is where the project gets concrete. It’s also the part I’d point to if someone asked which single decision moved the needle most.
Every property site has filters — type, location, number of bedrooms, tags like “luxury” or “private pool.” On this site the structure ran deep. The main sections were the property types: apartments, villas, townhouses, penthouses, houses. Each type then split by district, by bedroom count from one to five, and by a long list of tags — ocean view, private pool, off-plan, completed, freehold, leasehold, and more. The default way WordPress property sites handle all that filtering is with URL parameters, which produces addresses along these lines:
site.com/property/for-sale/villa?bedrooms=3&filter[0]=pool
For SEO purposes a URL like that is more or less dead weight. It’s unreadable, it generates an endless sprawl of near-duplicate combinations, and search engines mostly don’t want to index it anyway. But when we looked at our clustered keyword list — and there were thousands of keywords by this point — something jumped out. A large share of the clusters mapped almost one-to-one onto filter combinations. People weren’t searching the bare word “property.” They were searching “3 bedroom villa with pool [district],” “off-plan apartment [area]” — specific type-plus-bedrooms-plus-tag phrases. Every one of those was a cluster, and every cluster wanted its own page.
Now, multiply types by districts by bedroom counts by tags and the theoretical number of URLs runs into the tens of thousands. We did not build a page for every combination — that genuinely would be thin-content spam. Instead the clustering did the filtering for us. A combination got a real page only when there was actual search demand behind it, demand the keyword data could show. That left us with somewhere around 450 pages: every mid- and low-competition cluster that a real person was actually searching for, and nothing speculative.
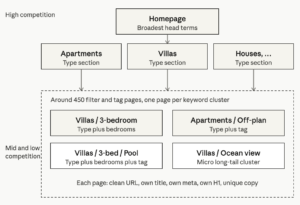
So we did the slower version. We rebuilt the filter system on clean, static, readable paths, one page per cluster:
site.com/buy/villas/3-bedroom/private-pool/
And each of those ~450 pages was treated as a proper landing page rather than a bare grid of listings. Mapped straight from its cluster, every one got:
It’s worth being precise about why this isn’t spam, because at 450 pages someone will ask. Thin-content spam is duplicated meta tags, cannibalizing pages, ugly parameter URLs, pages auto-generated with nothing unique on them. This was the opposite — a deliberate architecture where each page targets one real keyword cluster, down to the micro long-tail ones, each with its own clean URL, its own meta, its own H1 and copy. Volume of pages isn’t the problem. Duplication and emptiness are. These pages had neither.
One more thing we did with them, and it wasn’t only for SEO. All 450 were also surfaced as a set of tag pages — so a visitor could browse “private pool” or “ocean view” or “3 bedroom” directly, instead of being forced to assemble a filter every time. The same optimized pages doing double duty: a ranking landing page for Google, and a genuine navigation shortcut for the person on the site.
What made the whole thing work was the dull part: no duplication, anywhere. Plenty of people building property sites don’t bother with this, and I understand why — it’s real work, done page by page by page, 450 times over. But because each page came from its own distinct cluster, no two of them shared a title, a description, or a target intent. Every page was a unique landing page aimed at one search it could realistically win. There’s nothing sophisticated about it. It just usually gets skipped because it’s tedious.
Once the clusters are mapped to pages you have to decide what to do first. This is where “what are the best keywords for a real estate website” finally gets a useful answer — and the answer is not “the ones with the most searches.”
Sort the clusters into three competition tiers. For a site that isn’t already an established authority, the sensible play is to start at the bottom tier and work upward.
| Tier | What it looks like in real estate | When to target it |
|---|---|---|
| Low competition | Specific filter and long-tail phrases — “buy 2-bedroom villa [district]”, “long-term land rental [area]” | Start here. Quick wins, strong buyer intent, and each one builds the credibility you’ll need later. |
| Mid competition | Type-plus-intent terms — “villas for sale [city]”, “property for rent [region]” | Move here once the low-competition pages are indexed and pulling traffic. This tier holds the steady volume. |
| High competition | Broad head terms — “property for sale”, “real estate [country]” | Don’t open with these. You climb toward them. They also tend to convert worst per visit, so the rush isn’t worth much. |
Starting low isn’t about being modest. It’s just how the mechanics work out. A new or mid-strength real estate site has effectively no chance against the national portals on a head term — you can pour months into “property for sale” and get nowhere. But that same site can genuinely win a specific filter phrase, and each of those wins is a page earning traffic and slowly lifting what the whole domain can compete for. The low-competition keywords aren’t a consolation prize you settle for. They’re the on-ramp to everything above them. So when someone asks which keywords are best for a real estate website, the honest answer is: the most winnable ones you haven’t claimed yet.
This is exactly how the keywords landed on the property project. The handful of genuinely competitive head terms went on the homepage and the main type sections — apartments, villas, and so on. Those pages were never going to be quick wins, but they’re the right home for the hard terms. Everything below them, the mid- and low-competition clusters, went onto the roughly 450 filter and tag pages. The competition tiers weren’t an abstract idea on that project. They were the site’s actual architecture.
Filter and category pages catch people who are ready to act. Informational articles catch them earlier — while they’re still researching neighborhoods, the buying process, ownership rules — and that’s where a property site builds real depth. Two warnings here though, both of which I’ve learned the slightly-hard way.
Don’t write the popular topics. The instinct is to go for the obvious high-traffic subjects. On those you’re up against every established site that published them years ago, and you’ll probably lose. The articles actually worth writing are the specific, real, slightly-awkward questions your buyers genuinely ask — the ones with real demand where the competition hasn’t fully hardened yet. A narrow honest question tends to be a better bet than a broad popular one.
Cluster the articles too. Cannibalization isn’t only a transactional-page problem — people forget that. Two blog posts aimed at the same informational intent will compete with each other in exactly the same way two product pages would. So every article comes from its own cluster, same rule as the filter pages. One intent, one URL, across the whole site, blog included.
And it’s perfectly fine to place a phrase on purpose. This article is built around keywords for a real estate website as its actual subject, so the phrase belongs here — used where it genuinely describes the page and then left alone, not sprinkled around past the point of sounding natural. With an exact-match phrase, once is usually enough.
This next part is the one that’s shifted the most in the last couple of years, and it’s why “just publish lots of blog posts” has gone from harmless to genuinely risky advice.
There was a time when a thin, rewritten article was simply useless — it didn’t rank, but it didn’t really cost you anything either. I wouldn’t count on that anymore. Google has been moving, fairly openly, toward rewarding what tends to get called information gain: content that actually adds something that isn’t already sitting in the index. There’s a Google patent describing more or less this — scoring a document on how much new information it gives a reader beyond what they’d have already seen elsewhere on the topic.
I want to be careful here, because a lot of SEO writing takes that idea and inflates it into hard law. I genuinely can’t tell you Google deletes every rephrased article — I don’t know that, and neither does anyone confidently claiming it. What I can tell you is what I keep seeing when I audit blogs: pages that just restate what the current top results already say tend not to earn rankings, and when a site is carrying a large mass of that low-value content, it does seem to weigh on how the rest of the site is judged. Whether the real mechanism is some “domain quality” score or something else entirely, I don’t know. The practical takeaway holds up regardless. A blog full of rephrased filler isn’t a neutral thing sitting harmlessly in a corner. Best case it was wasted effort. Worst case it’s actively holding back the pages you care about.
So the standard for a real estate blog isn’t word count. Each article has to carry something real. Your own experience from actual deals. Local knowledge a national portal will never have. Real numbers, a first-hand account of how a sale actually went. A property agency is sitting on all of this already. You have real transactions, real neighborhoods, the questions clients ask you over and over. A competitor rewriting generic advice from page one has none of that, and that gap is your whole advantage. Most agencies just never write any of it down.
Google calls the broader idea E-E-A-T: Experience, Expertise, Authoritativeness, Trust. The part people skip is the first E. An article needs a real author behind it, and that author needs to actually exist somewhere else on the web. A name with no bio, no photo, no trace of any prior work gives a trust assessment nothing to hold onto. So put a real person on the article, with real credentials, writing from real experience. This isn’t decoration you add at the end. It’s structural, same as the headings.
Quality needs checking twice — once before a piece goes live, and once across everything you’ve already published.
Before publishing, check the article itself. Read it honestly before it goes up. Does it add anything, or is it a well-written version of what’s already ranking? Does a real person and real expertise come through? Is the keyword sitting there naturally, or jammed in? Do this by hand at least a few times — you need to calibrate your own eye before you trust any tool to do it. A text-audit tool helps mainly with consistency once a team is involved; ours scores information gain and E-E-A-T together, and there are others. The value is catching a weak article before it’s published, not after.
Then audit the blog you already have. Most established agencies already run a blog, and that’s where the bigger problem usually hides. It’s not one article, it’s forty of them, half thin and rephrased, all sitting there doing nothing good. A content audit across the whole blog is how you find them. Then each weak page gets a verdict: rewrite it properly, merge it into something stronger, or delete it. Deleting pages feels wrong to people — it shouldn’t. Cutting dead weight so the site’s strength concentrates on pages that earn their place is one of the best moves available on an older property site.
The last step connects the blog to the actual business. It’s also the one everyone forgets once the writing is done.
Don’t let informational articles sit off in their own blog silo. An article on how to choose a neighborhood should link straight to the relevant filter and category pages — the buyer-facing pages you built earlier — wherever it naturally makes sense in the text. There are two reasons for it. One is for the reader: someone still researching gets a path toward the pages where they can actually do something. The other is for SEO: the link passes ranking signal from your content over to the transactional pages, which is exactly the help they need to climb toward the harder terms.
Do this across the blog and the internal links stop being decoration. They become structure — research articles feeding the money pages, every page reinforcing its own cluster. That’s the thing the whole workflow has been heading toward since step one.
Here’s the whole sequence in one place. Collect the keyword set wide, without filtering. Cluster it by intent, so the keywords decide your pages instead of the other way around. Map every cluster to exactly one page — and that includes turning filters into clean landing pages, each with its own meta, none of it duplicated. Prioritize by competition tier and start at the bottom. Add informational articles with real information gain and a real author, each from its own cluster. Check quality before you publish, and audit the blog you already have. Then link the articles back to the pages that make money.
Individually none of these steps is hard. What people skip is the middle — the clustering, the discipline of never duplicating, the honest look at whether an article deserves to exist. That middle is where the result actually comes from. And it’s the real answer to which keywords are best for a real estate website: not the ones with the biggest numbers, but the winnable clusters mapped onto pages that don’t fight each other. Finding them is a process, not a list you can copy from somewhere.
We run this workflow for property businesses that live on organic traffic — the first keyword pull, the clustering, the content, and the audits that keep a blog earning its place instead of dragging the site down. If your site needs that kind of structured work, that’s what we do.